DATA STRUCTURE SUMMARY
Linked List
Like arrays, Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
1. SINGLE LINKED LIST
To CREATE a linked list, we first need to define a node structure for the list.
SEARCH
Let the key that we want to search is X.
DELETION
Like arrays, Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
1. SINGLE LINKED LIST
To CREATE a linked list, we first need to define a node structure for the list.
struct
tnode {
int value;
struct tnode *next;
};
struct
tnode *head = 0;
To INSERT a new value, first we should dynamically allocate a new node and assign the value to it and then connect it with the existing linked list.
struct
tnode *node =(struct tnode*) malloc(sizeof(struct tnode));
node->value = x;
node->next
= head;
head = node;
To DELETE a value, first we should find the location of node which store the value we want to delete, remove it, and connect the remaining linked list. There are 2 conditions, when the deleted value is on the head and not on the head.
struct tnode *curr = head;
//
if x is in head node
if ( head->value == x ) {
head
= head->next;
free(curr);
}
//
if x is not in head node, find the location
else {
while
( curr->next->value != x ) curr = curr->next;
struct
tnode *del = curr->next;
curr->next
= del->next;
free(del);
}
2. DOUBLE LINKED LIST
is a linked list data structure with two link, one that contain reference to the next data and one that contain reference to the previous data.
INSERT. Just like in a single linked list, first we should allocate the new node and assign the value to it, and then we connect the node with the existing linked list. Supposed we want to append the new node behind the tail.
struct
tnode *node = (struct tnode*) malloc(sizeof(struct tnode));
node->value = x;
node->next
= NULL;
node->prev
= tail;
tail->next
= node;
tail = node;
Supposed we want to insert a new node in a certain position (any location between head and tail)
struct
tnode *a = ??;
struct
tnode *b = ??;
// the new node will be inserted between
a and b
struct
tnode *node =
(struct tnode*)
malloc(sizeof(struct tnode));
node->value = x;
node->next = b;
node->prev = a;
a->next = node;
b->prev = node;
DELETE
4. QUEUE
If the node to be deleted is the only node:
free(head);
head = NULL;
tail = NULL;
If the node to be deleted is head:
head = head->next;
free(head->prev);
head->prev = NULL;
If the node to be deleted is tail:
tail = tail->prev;
free(tail->next);
tail-next = NULL;
If the node to be deleted is not in head or tail:
struct tnode *curr = head;
while ( curr->next->value != x ) curr =
curr->next;
struct tnode *a = curr;
struct tnode *del = curr->next;
struct tnode *b = curr->next->next;
a->next = b;
b->prev = a;
free(del);
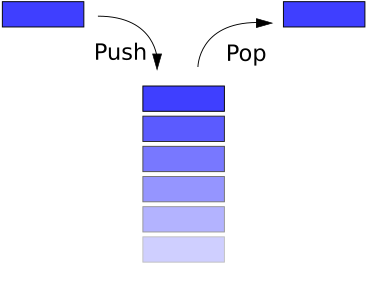
4. STACK
A stack is a basic data structure that can be logically thought of as a linear structure represented by a
real physical stack or pile, a structure where insertion and deletion of items takes place at one end called
top of the stack. The basic concept can be illustrated by thinking of your data set as a stack of plates or
books where you can only take the top item off the stack in order to remove things from it. This structure
is used all throughout programming.
The basic implementation of a stack is also called a LIFO (Last In First Out) to demonstrate the way it
accesses data, since as we will see there are various variations of stack implementations
push(x) : add an item x to the top of the stack.
pop() : remove an item from the top of the stack.
top() : reveal/return the top item from the stack
INSERTION
struct
stack *push (struct stack *top, int val){
struct stack *ptr;
ptr = (struct stack*) malloc (sizeof(struct
stack*));
ptr -> data = val;
if (top == NULL){
top = ptr;
top -> next = NULL;
} else {
ptr -> next = top;
top = ptr;
}
return top;
}
DELETION
struct stack *pop (struct stack *top){
struct stack *ptr;
ptr = top;
if (top == NULL){
printf(“\n STACK UNDERFLOW”);
} else {
top = top -> next;
printf(“\nThe deleted value: %d”, ptr -> data);
free(ptr);
}
return top;
}
DISPLAY
struct
stack *display(struct stack *top){
struct stack *ptr;
ptr = top;
if (top == NULL){
printf(“\n STACK IS EMPTY”);
} else {
while(ptr != NULL){
printf(“\n%d”, ptr -> data);
ptr = ptr -> next;
}
}
return top;
}
INFIX PREFIX POSTFIX NOTATION
Prefix
|
Infix
|
Postfix
|
* 4 10
|
4 * 10
|
4 10 *
|
+ 5 * 3 4
|
5 + 3 * 4
|
5 3 4 * +
|
+ 4 / * 6 – 5 2 3
|
4 + 6 * (5 – 2) / 3
|
4 6 5 2 – * 3 /
+
|
4. QUEUE
A queue is a basic data structure that is used throughout programming. You can think of it as a line in a grocery store. The first one in the line is the first one to be served.Just like a queue.
A queue is also called a FIFO (First In First Out) to demonstrate the way it accesses data.
push(x) : add an item x to the back of the queue.
pop() : remove an item from the front of the queue.
peak() : reveal/return the most front item from the queue.
INSERTION
void insert(){
int num;
printf(“\nEnter number to be inserted : “);
scanf(“%d”,&num);
if (rear == MAX-1) printf (“\n OVERFLOW”);
if (front == -1 && rear == -1)
front = rear = 0;
else
rear++;
queue[rear] = num;
}
DELETION
void delete_element(){
int val;
if (front == -1 || front>rear){
printf(“\n UNDERFLOW”);
return -1;
}
else {
front++;
val = queue[front]
return val;
}
}
DISPLAY
void display(){
int i;
printf(“\n”);
for (i=front; i<=rear; i++)
printf(“\t %d”, queue[i]);
}
5. HASHING AND HASH TABLE
HASH TABLE
- Hash table is a table (array) where we store the original string. Index of the table is the hashed
key while the value is the original string.
- The size of hash table is usually several orders of magnitude lower than the total number of
possible string, so several string might have a same hashed-key.
HASHING
- Hashing is a technique used for storing and retrieving keys in a rapid manner.
- In hashing, a string of characters are transformed into a usually shorter length value or key
that represents the original string.
- Hashing is used to index and retrieve items in a database because it is faster to find item using
shorter hashed key than to find it using the original value.
- Hashing can also be defined as a concept of distributing keys in an array called a hash table
using a predetermined function called hash function.
•There
are many ways to hash a string into a key. The following are some of the
important methods for constructing hash functions.
•Mid-square
Square the string/identifier and then using an appropriate number of bits from the
middle of the square to obtain the hash-key.
Function : h(k) = s
k = key
s = the hash key obtained by selecting r bits from k2
•Division (most common)
Divide the string/identifier by using the modulus operator.
Function: h(z) = z mod M
z = key
M = the value using to divide the key, usually using a prime number, the table size or the size of memory used.
•Folding
•The Folding method works in two
steps :
–Divide the key value into a number
of parts where each part has the same number of digits except the last part
which may have lesser digits than the other parts.
–Add the individual parts. That is
obtain the sum of part1 + part2 + ... + part n. The hash value produced by
ignoring the last carry, if any.
•Digit Extraction
A predefined digit of the given number is considered as the hash address.
•Rotating Hash
•Use
any hash method (such as division or mid-square method)
•After
getting the hash code/address from the hash method, do rotation
•Rotation
is performed by shifting the digits to get a new hash address.
•Example:
–Given
hash address = 20021
–Rotation
result: 12002 (fold the digits)
COLLISION
is a situation that occurs when two distinct pieces of data have the same hash value.
There are two general ways to
handle collisions:
•Linear
Probing
Search
the next empty slot and put the string there.
void
linear_probing(item, h[]) {
hash_key = hash(item);
i = has_key;
while ( strlen(h[i] != 0 ) {
if ( strcmp(h[i], item) == 0 ) {
// DUPLICATE ENTRY
}
}
i = (i + 1) % TABLE_SIZE;
if ( i == hash_key ) {
// TABLE IS FULL
}
}
}
}
h[i] = item;
}
}
•Chaining
Put
the string in a slot as a chained list (linked list).
void
chaining(item, h[]) {
hash_key = hash(item);
trail = NULL, lead = h[hash_key];
while ( lead ) {
if ( strcmp(lead->item, item) == 0 ) {
// DUPLICATE ENTRY
}
trail = lead; lead = lead->next;
}
}
p = malloc new node;
p->item = item;
p->next = NULL;
if ( trail == 0 ) h[hash_key] = p;
else trail->next = p;
}
5. BINARY SEARCH TREE
•Binary Search Tree (BST) is one
such data structures that supports faster searching, rapid sorting,
and easy
insertion and deletion
•BST is also known as sorted
versions of binary tree
•For a node x in of a BST T,
–the left
subtree of x contains
elements that are smaller than
those stored in x,
–the right
subtree of x contains
all elements that are greater than
those stored in x,
with
the assumptions that the keys are distinct
Let the key that we want to search is X.
- We begin at root
- If the root contains X then search
terminates successfully.
- If X is less than root’s key then
search recursively on left sub tree, otherwise search recursively on right sub
tree.
struct node* search (struct node *curr, int X) {
if ( curr == NULL ) return NULL;
// X is found
if ( X == curr->data ) return curr;
// X is located in left sub tree
if ( X < curr->data ) return find(curr->left, X);
// X is located in right sub tree
return find(curr->right, X);
}
INSERTION
Let the new node’s key be X,
- Begin at root
- If X is less than node’s key then insert X into left sub tree, otherwise insert X into right sub tree
- Repeat until we found an empty node to put X (X will always be a new leaf)
struct node* insert(struct node* node, int key)
{
/* If the tree is empty, return a new node */
if (node == NULL) return newNode(key);
/* Otherwise, recur down the tree */
if (key < node->key)
node->left = insert(node->left, key);
else if (key > node->key)
node->right = insert(node->right, key);
/* return the (unchanged) node pointer */
return node;
}
DELETION
There
are 3 cases which should be considered:
- If
the key is in a leaf, just delete that node
- If
the key is in a node which has one child, delete that node and connect its
child to its parent
- If
the key is in a node which has two children, find the right most child of its
left sub tree
(node P), replace its key with P’s key and remove P recursively.
(or alternately you can choose
the left most child of its right sub tree)
struct node* deleteNode(struct node* root, int key)
{
{
// base case
if (root == NULL) return root;
// If the key to be deleted is smaller than the root's key,
// then it lies in left subtree
if (key < root->key)
root->left = deleteNode(root->left, key);
// If the key to be deleted is greater than the root's key,
// then it lies in right subtree
else if (key > root->key)
root->right = deleteNode(root->right, key);
// if key is same as root's key, then This is the node
// to be deleted
else
{
// node with only one child or no child
if (root->left == NULL)
{
struct node *temp = root->right;
free(root);
return temp;
}
else if (root->right == NULL)
{
struct node *temp = root->left;
free(root);
return temp;
}
// node with two children: Get the inorder successor (smallest
// in the right subtree)
struct node* temp = minValueNode(root->right);
// Copy the inorder successor's content to this node
root->key = temp->key;
// Delete the inorder successor
root->right = deleteNode(root->right, temp->key);
}
return root;
}

Comments
Post a Comment